SemanticDraw: Towards Real-Time Interactive Content Creation from Image Diffusion Models
Computer Vision Lab, Seoul National University
![]()
CVPR 2025
SemanticDraw: Towards Real-Time Interactive Content Creation from Image Diffusion Models
Computer Vision Lab, Seoul National University
![]()
CVPR 2025
Semantic Draw turns any image diffusion model into a live paintbrush tool that let you brush semantic intent—not just color pixels.

Abstract
We introduce SemanticDraw, a new paradigm of interactive content creation where high-quality images are generated in near real-time from given multiple hand-drawn regions, each encoding prescribed semantic meaning. In order to maximize the productivity of content creators and to fully realize their artistic imagination, it requires both quick interactive interfaces and fine-grained regional controls in their tools. Despite astonishing generation quality from recent diffusion models, we find that existing approaches for regional controllability are very slow (52 seconds for 512 x 512 image) while not compatible with acceleration methods such as LCM, blocking their huge potential in interactive content creation. From this observation, we build our solution for interactive content creation in two steps: (1) we establish compatibility between region-based controls and acceleration techniques for diffusion models, maintaining high fidelity of multi-prompt image generation with x 10 reduced number of inference steps, (2) we increase the generation throughput with our new multi-prompt stream batch pipeline, enabling low-latency generation from multiple, region-based text prompts on a single RTX 2080 Ti GPU. Our proposed framework is generalizable to any existing diffusion models and acceleration schedulers, allowing sub-second (0.64 seconds) image content creation application upon well-established image diffusion models.
Stable Acceleration of Region-Based Image Generation
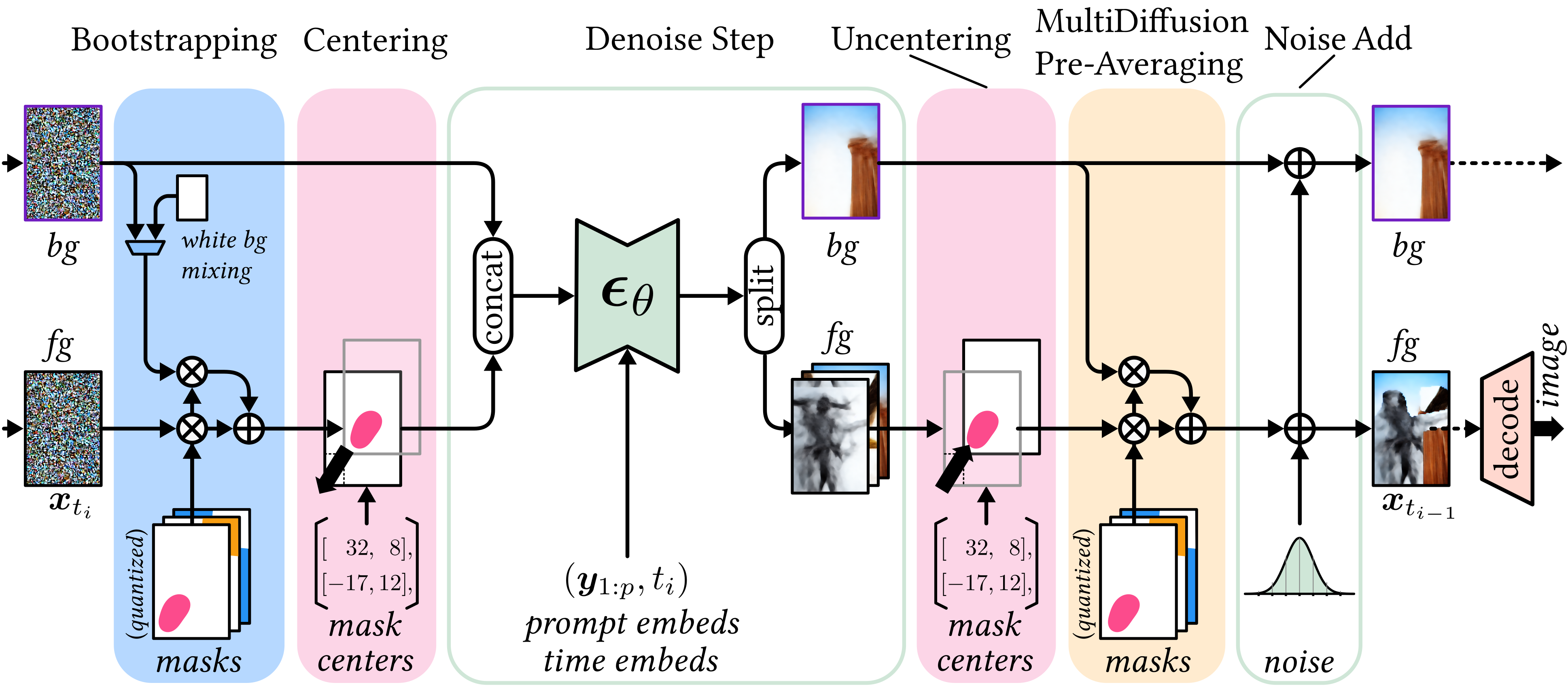
We establish the compatibility between region-based control [1] and acceleration [2] techniques for diffusion models.
Semantic Palette
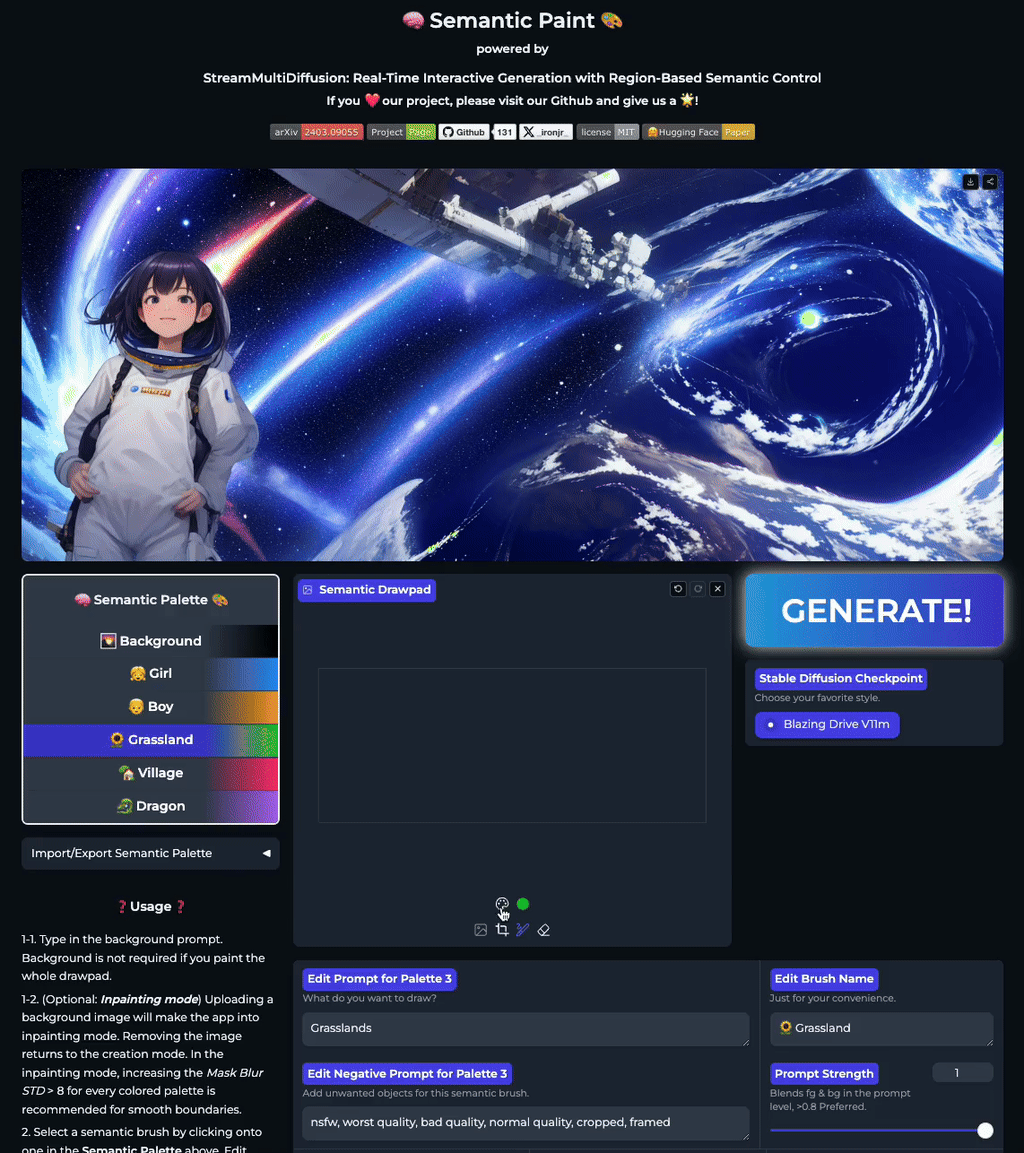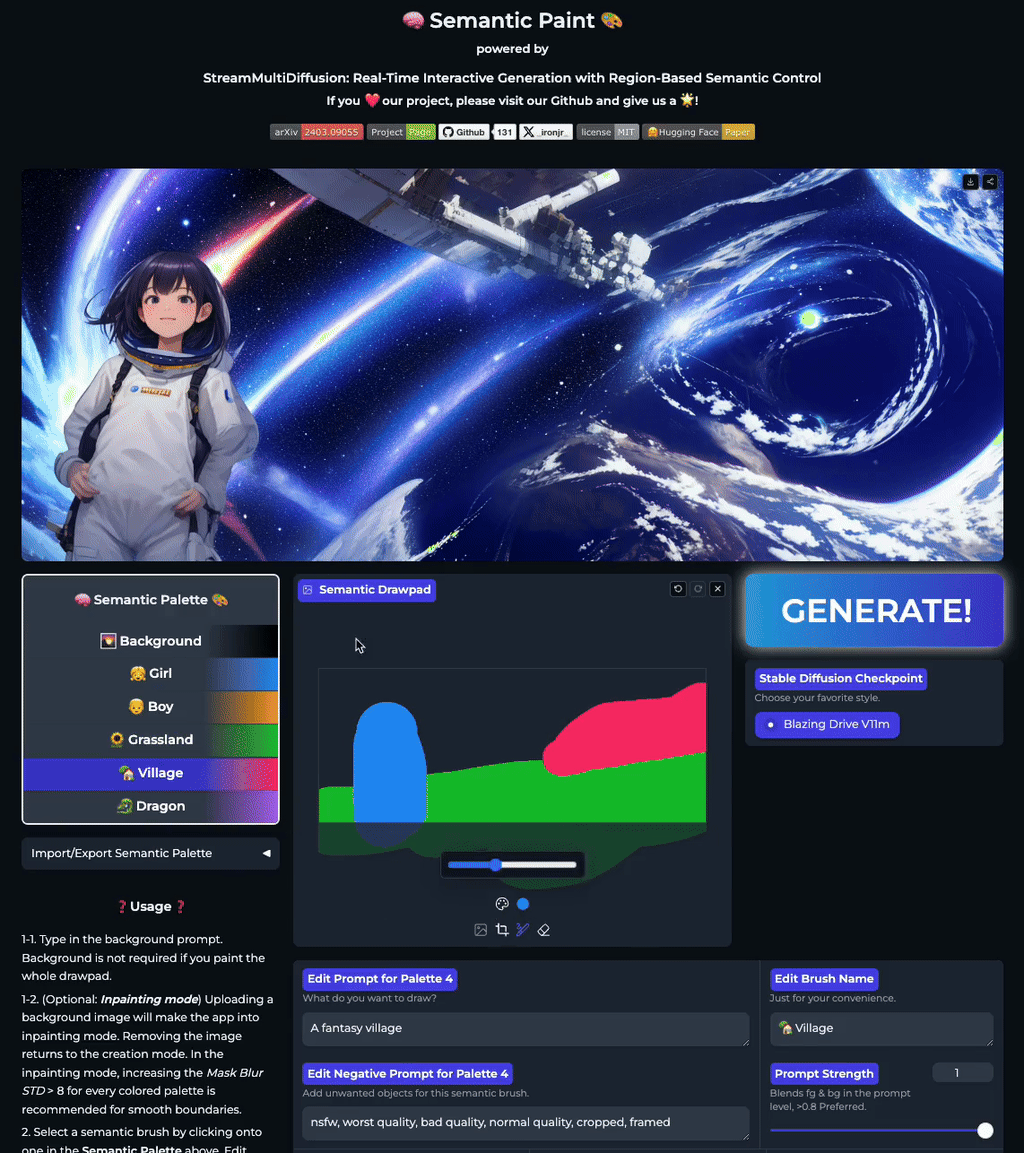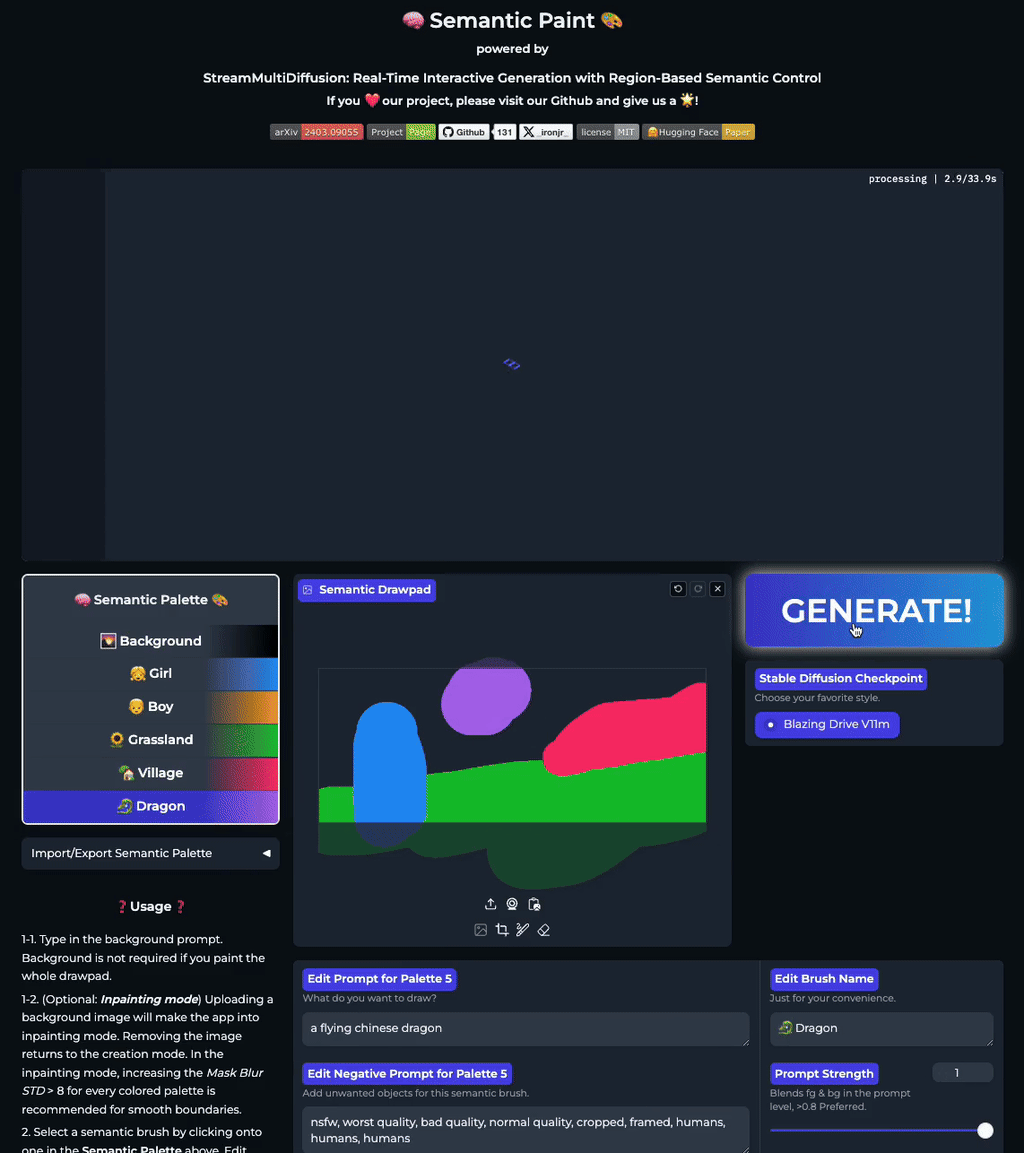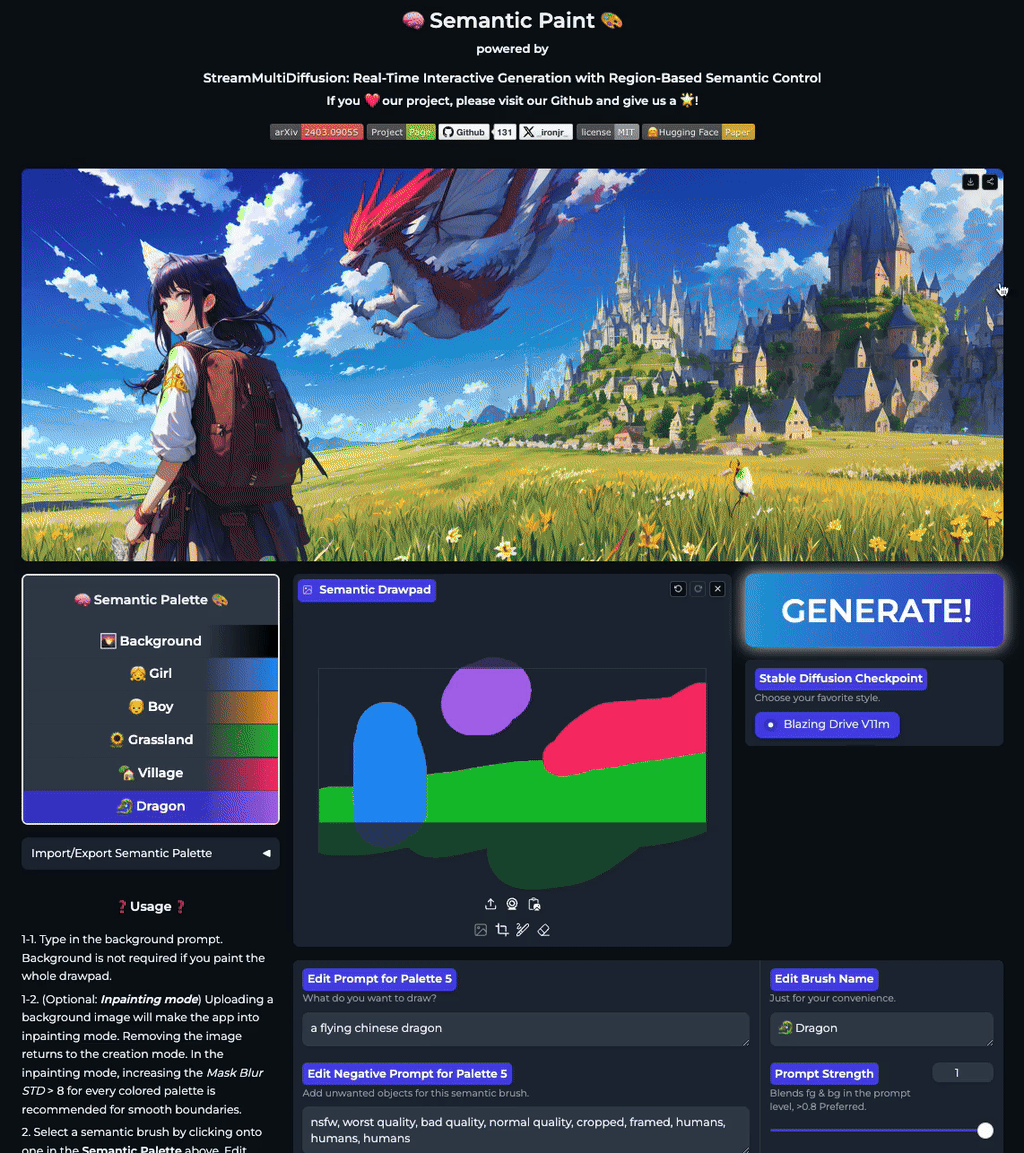
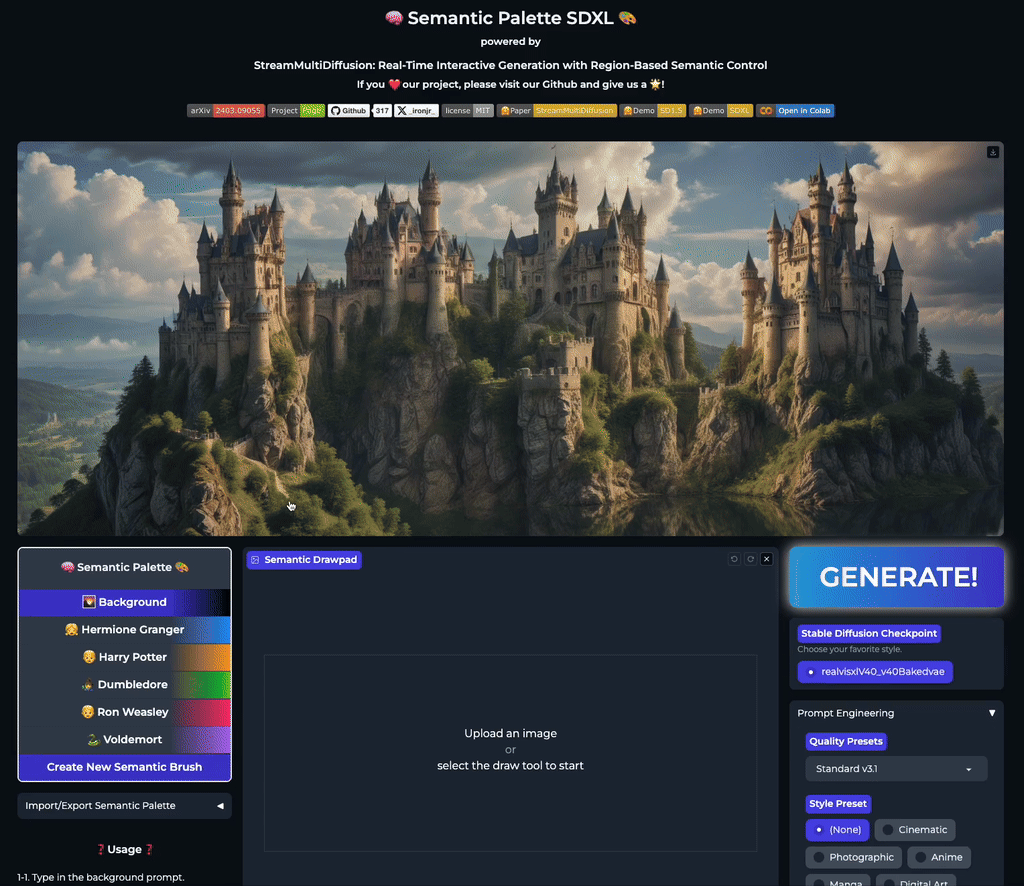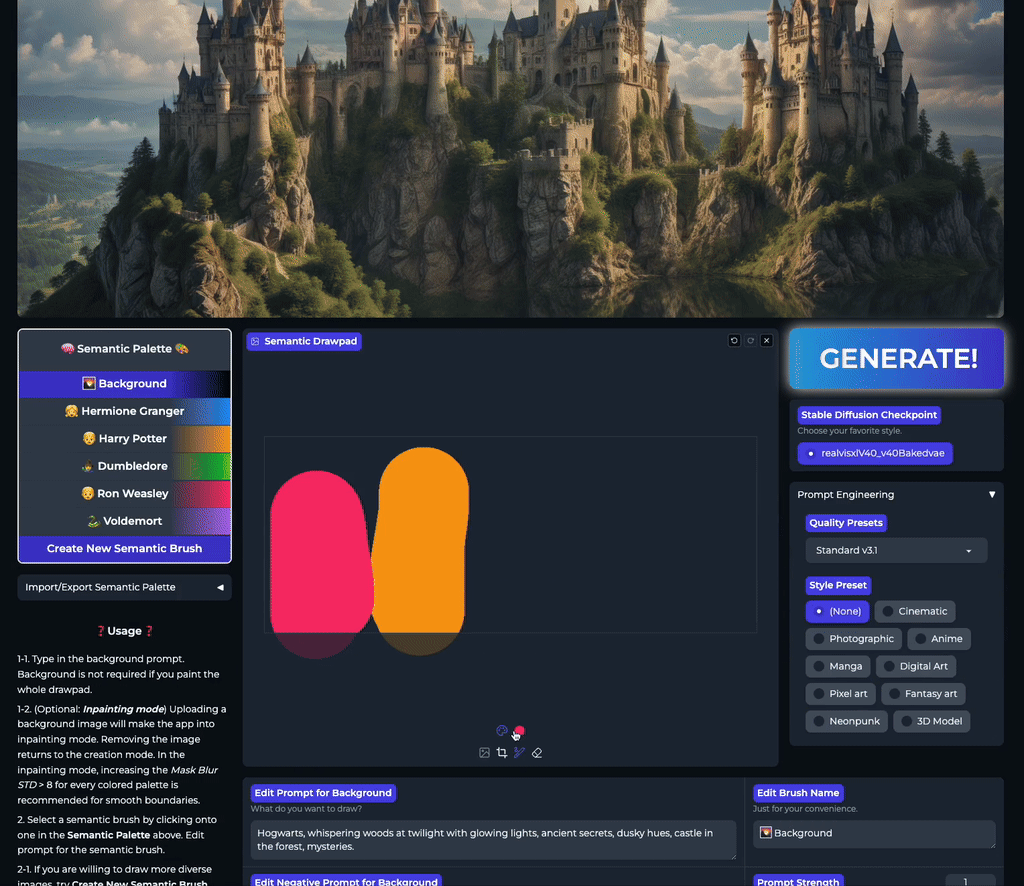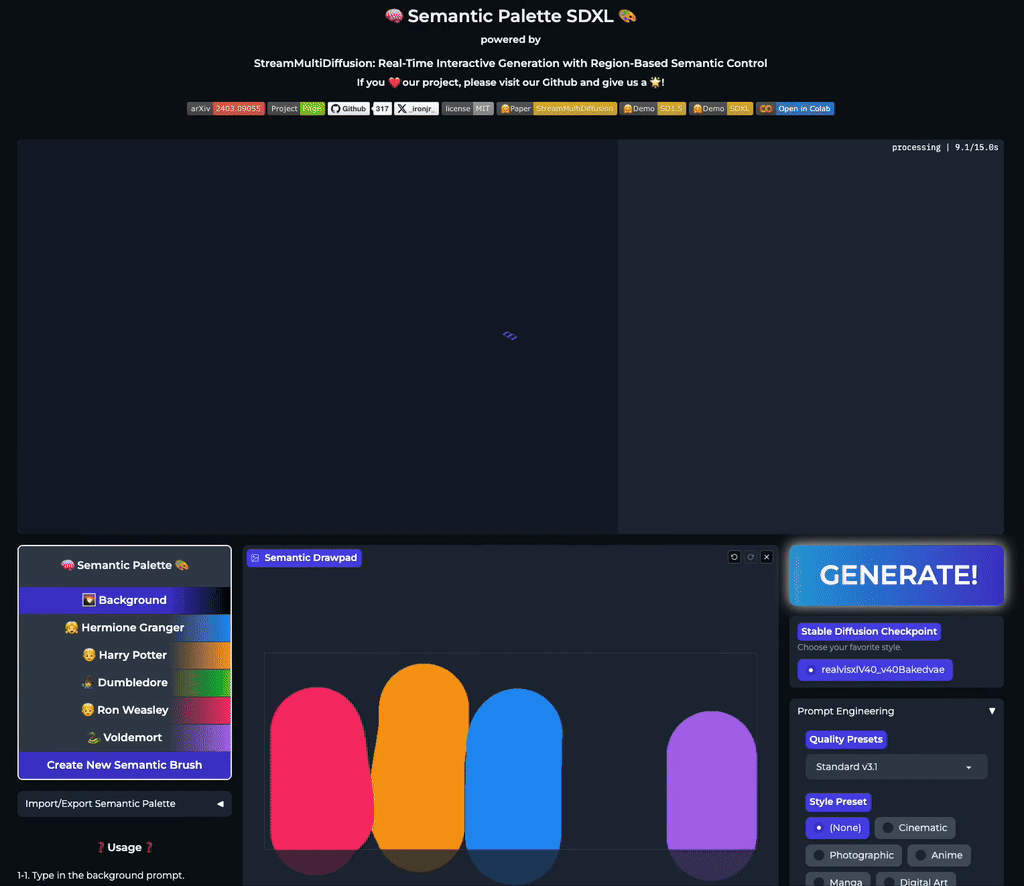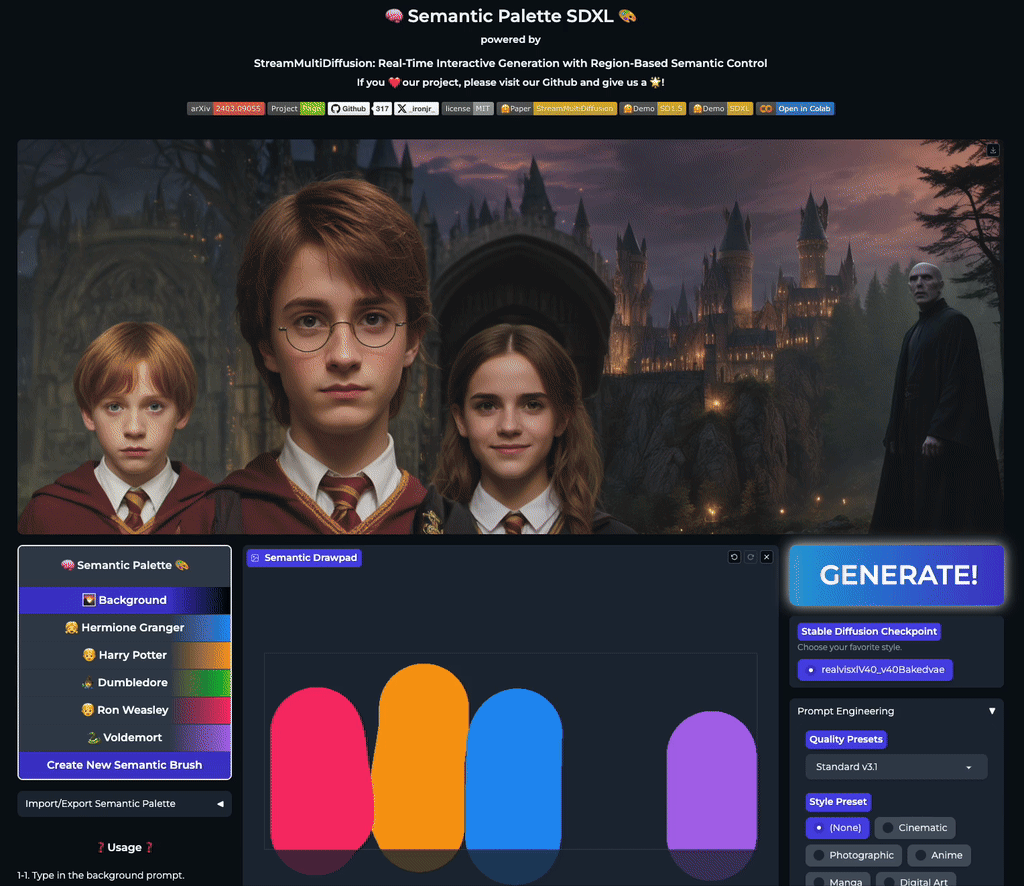
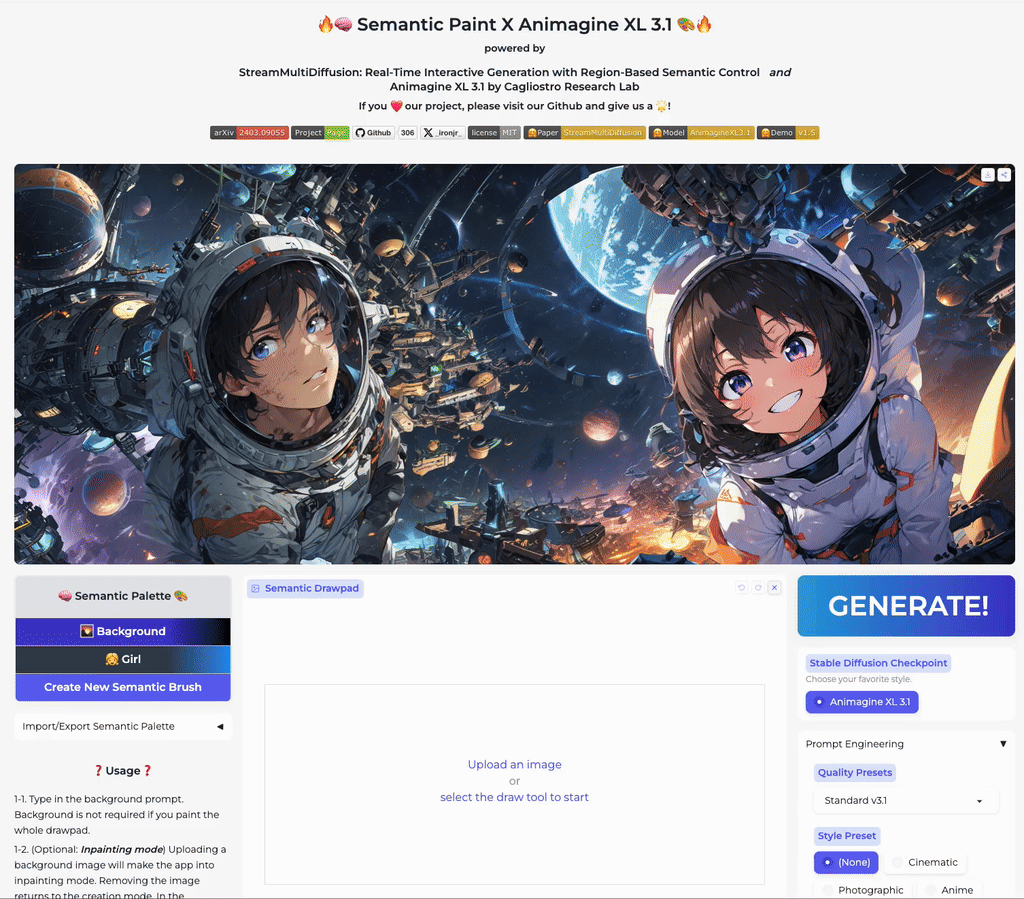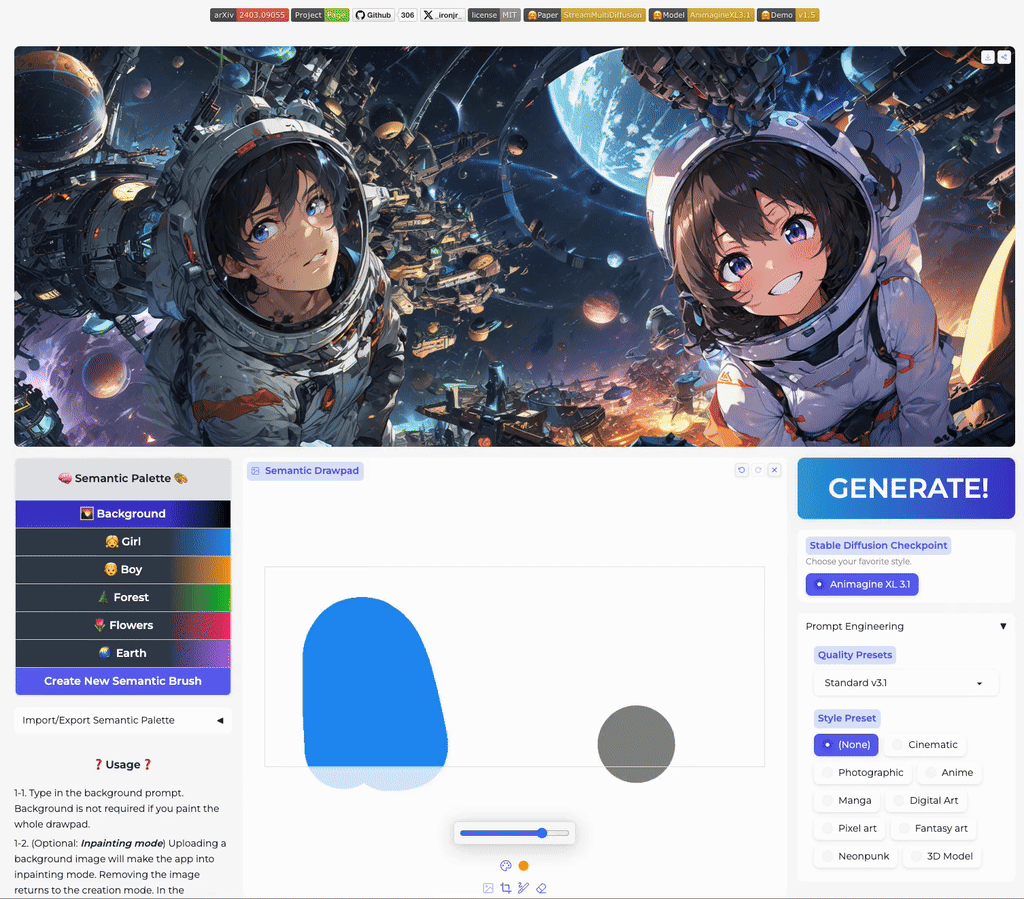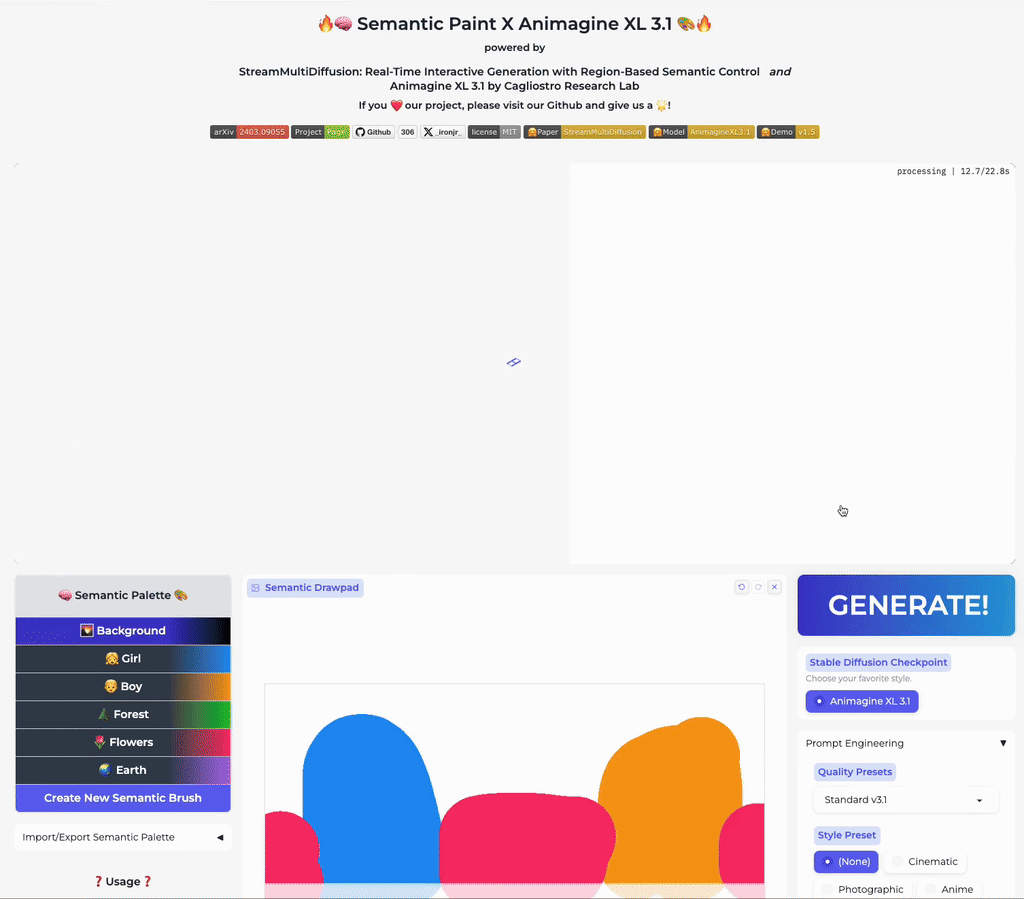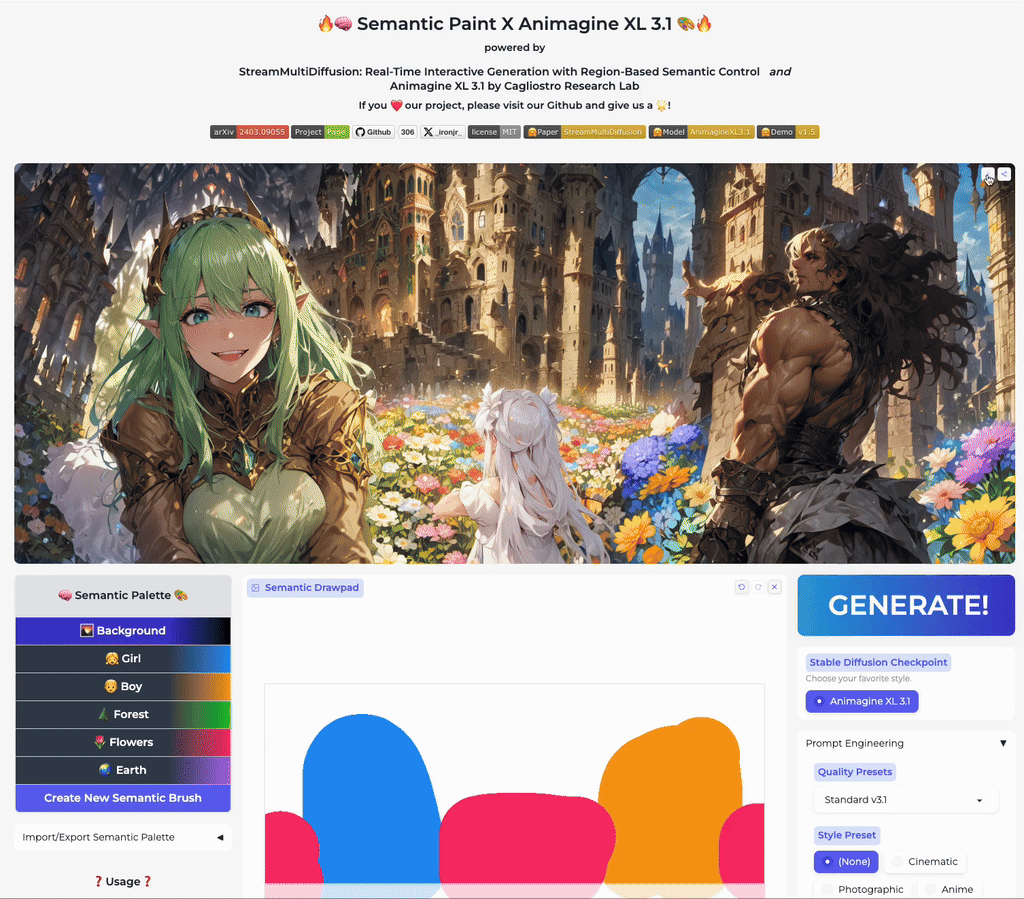
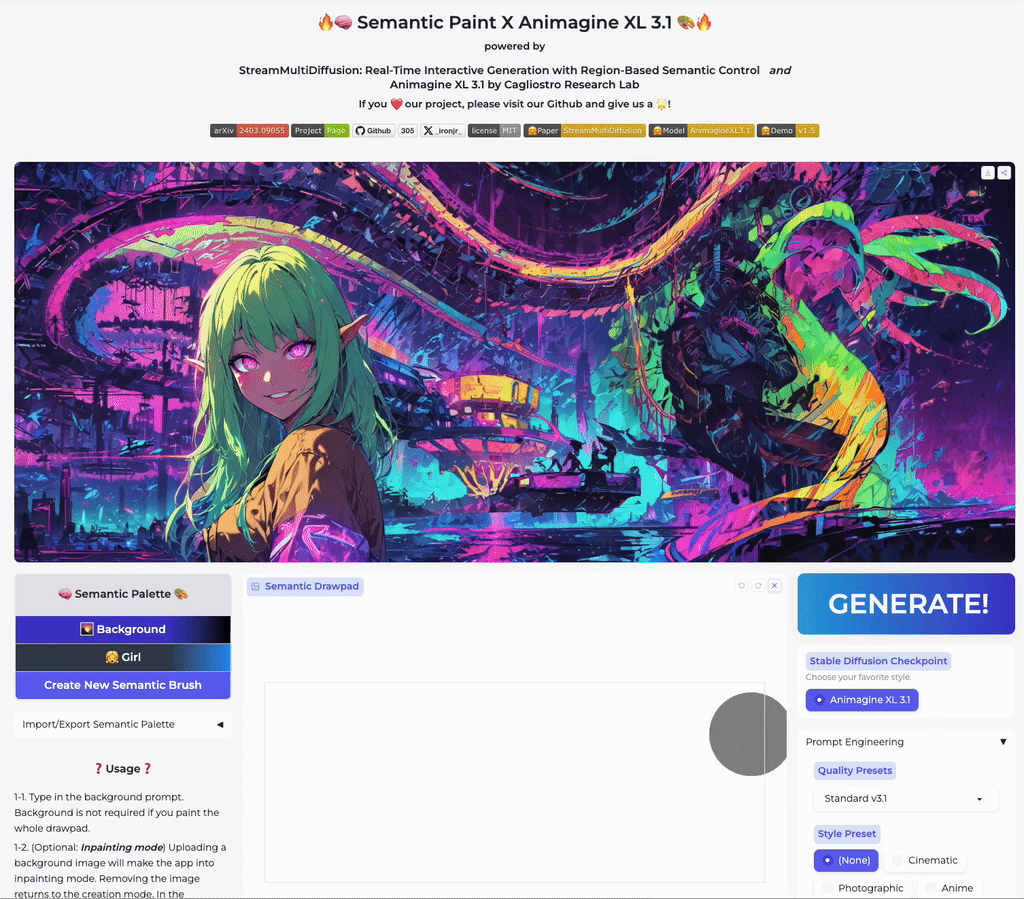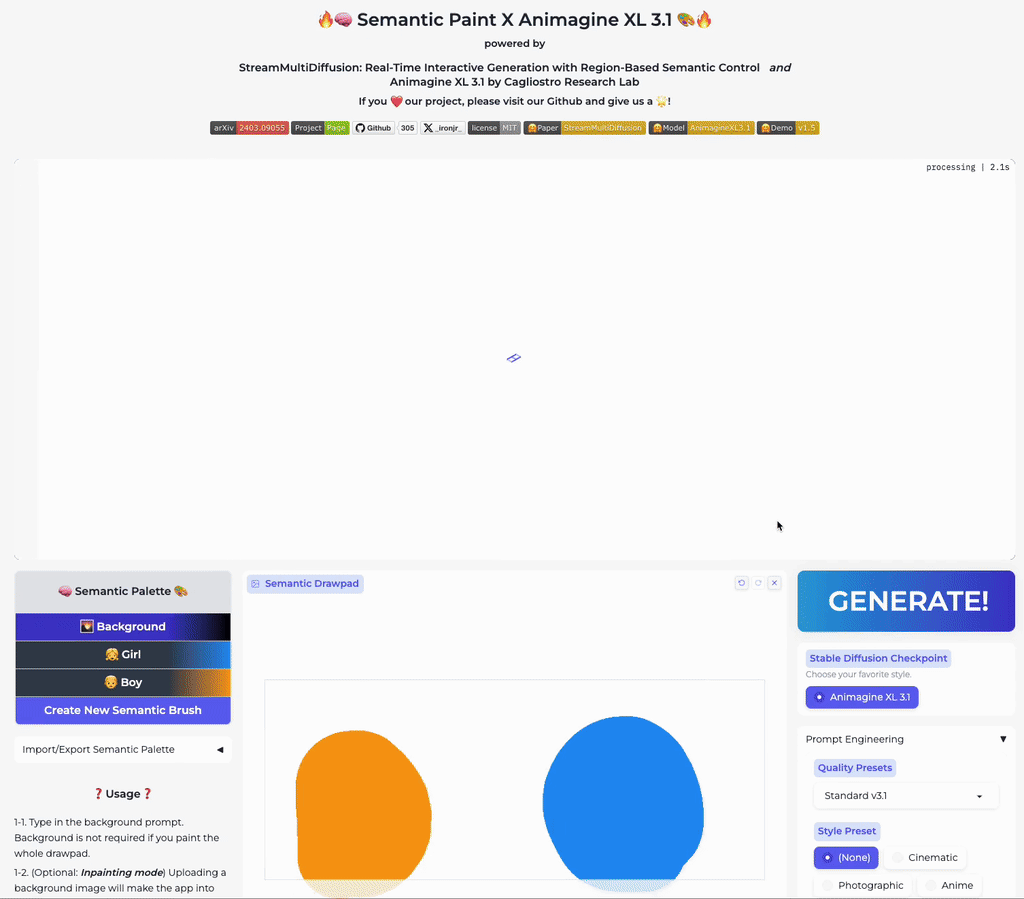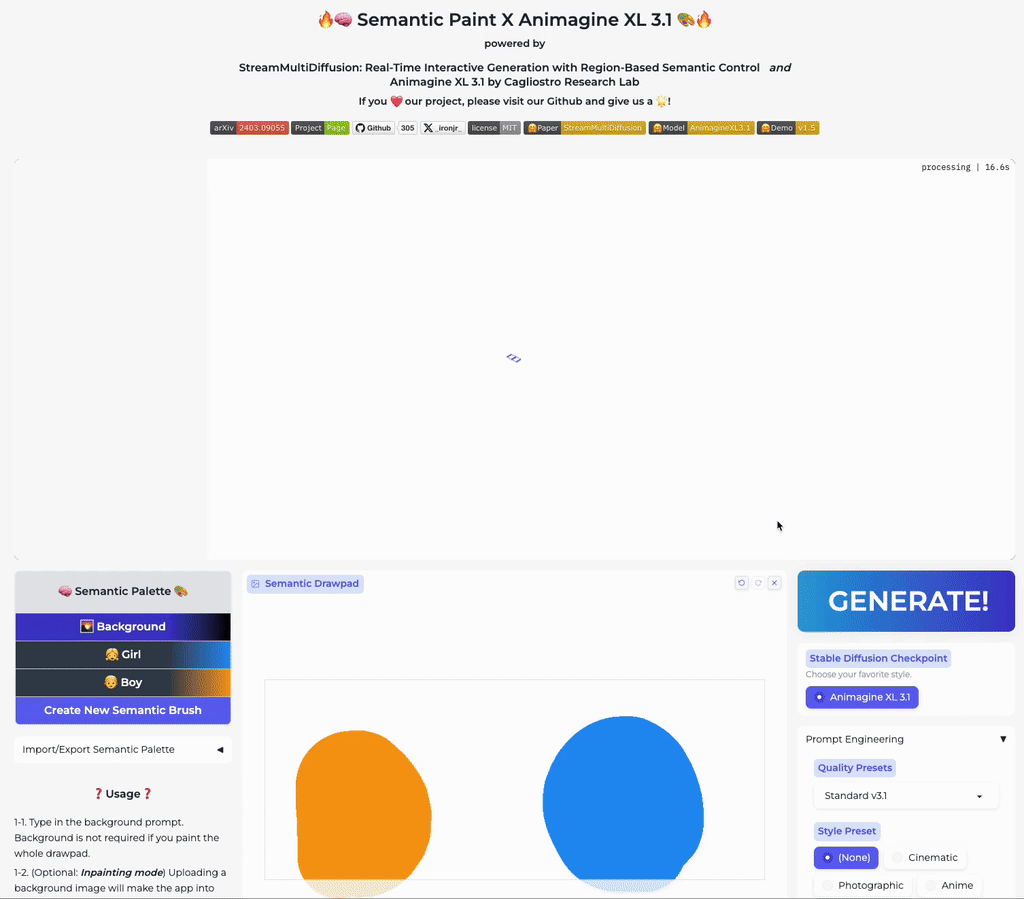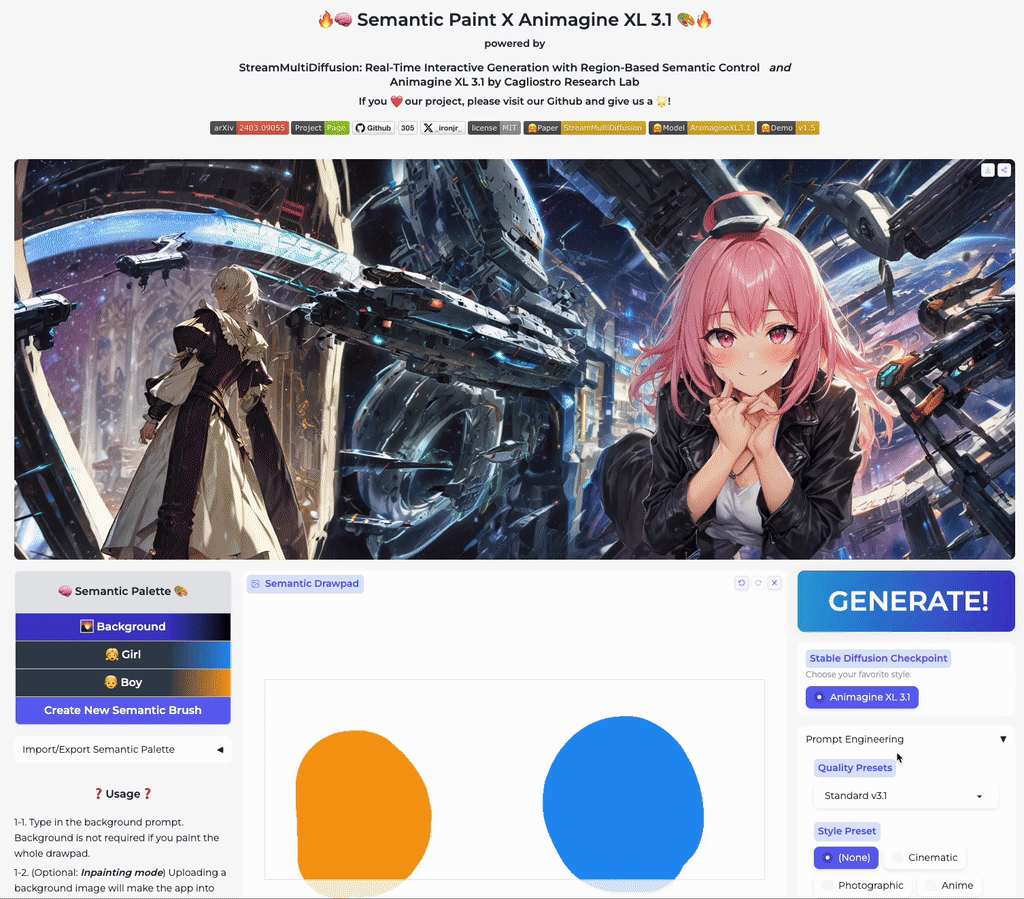
Our stable acceleration technique allows practical applications of large size image generation with fine-grained regional prompt control. In this first demo, we demonstrate arbitrary-sized image generation from arbitrary number of prompt-mask pairs. Try now from our code or at the official Hugging Face space demo. Note that our generation results also obeys strict prompt separation.
Multi-Prompt Stream Batch Architecture
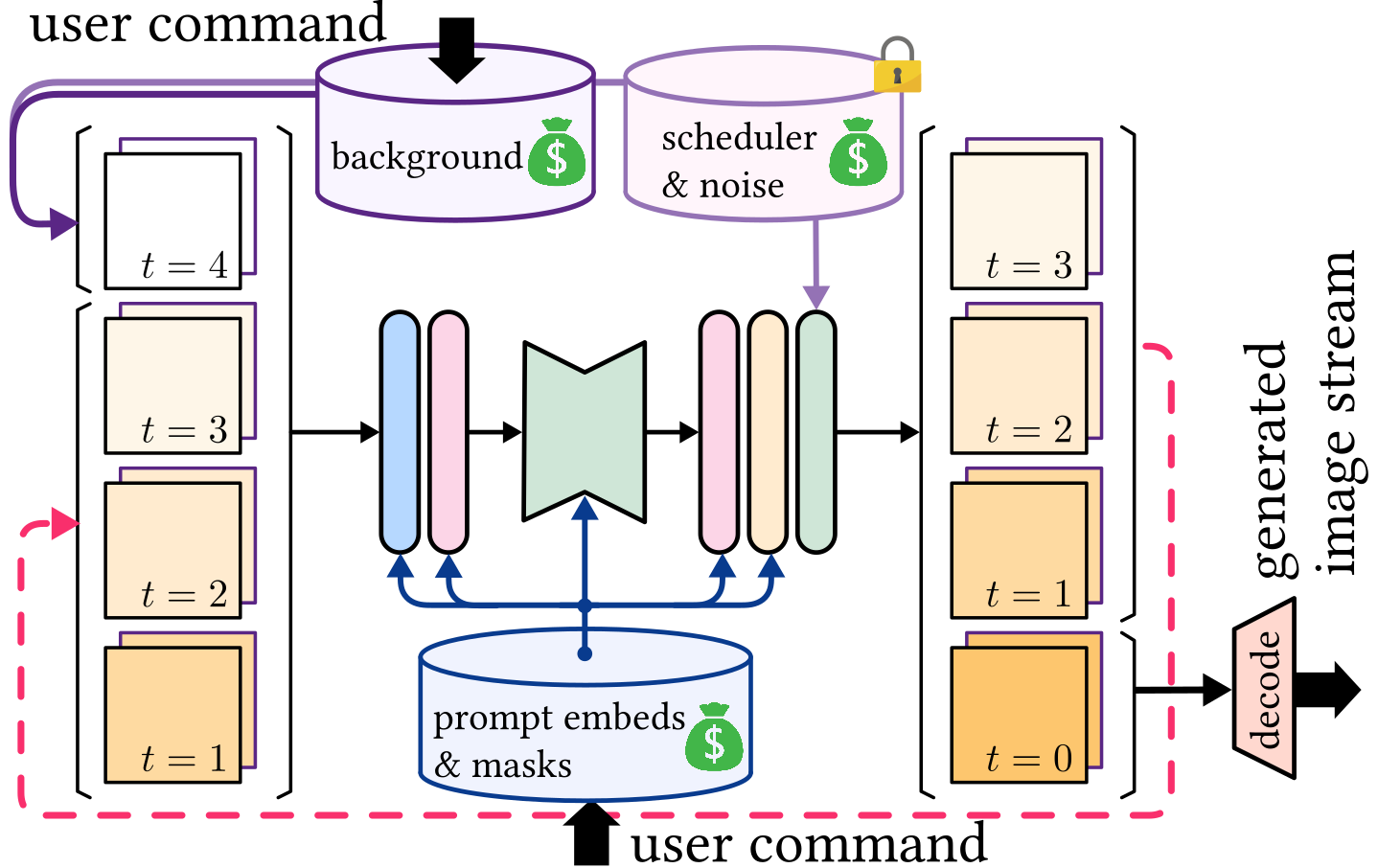
We extend Stream Batch architecture of StreamDiffusion [3] to allow streamed generation from multiple region-based text prompts.
Real-Time Semantic Palette
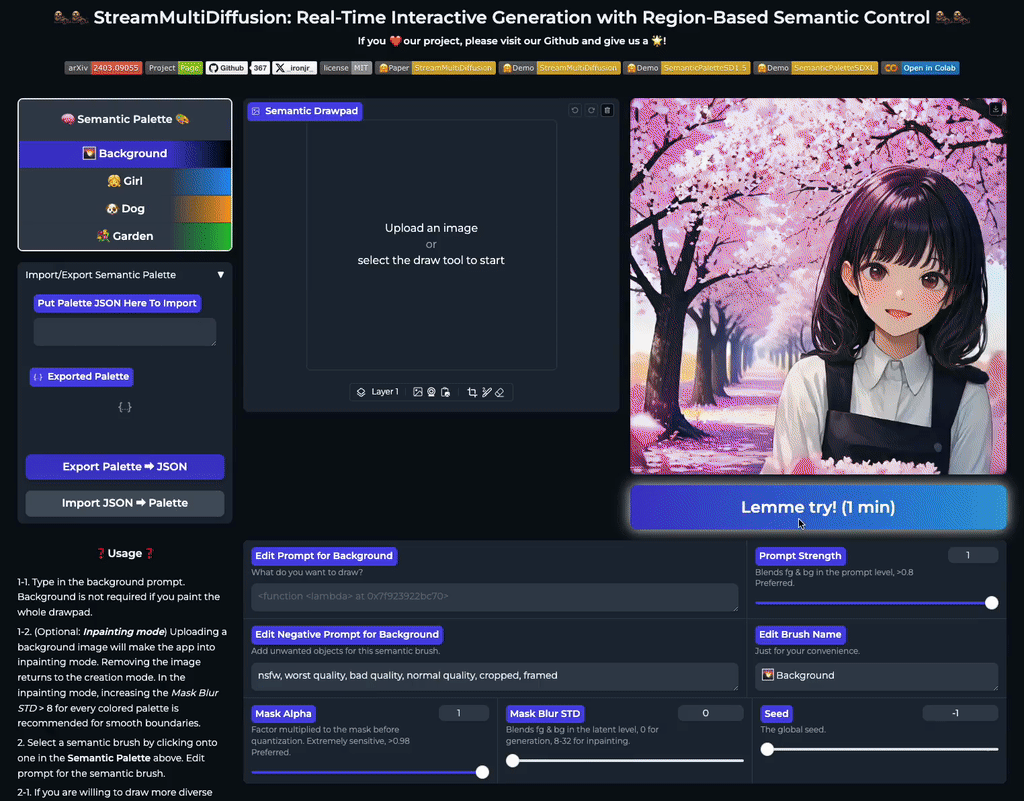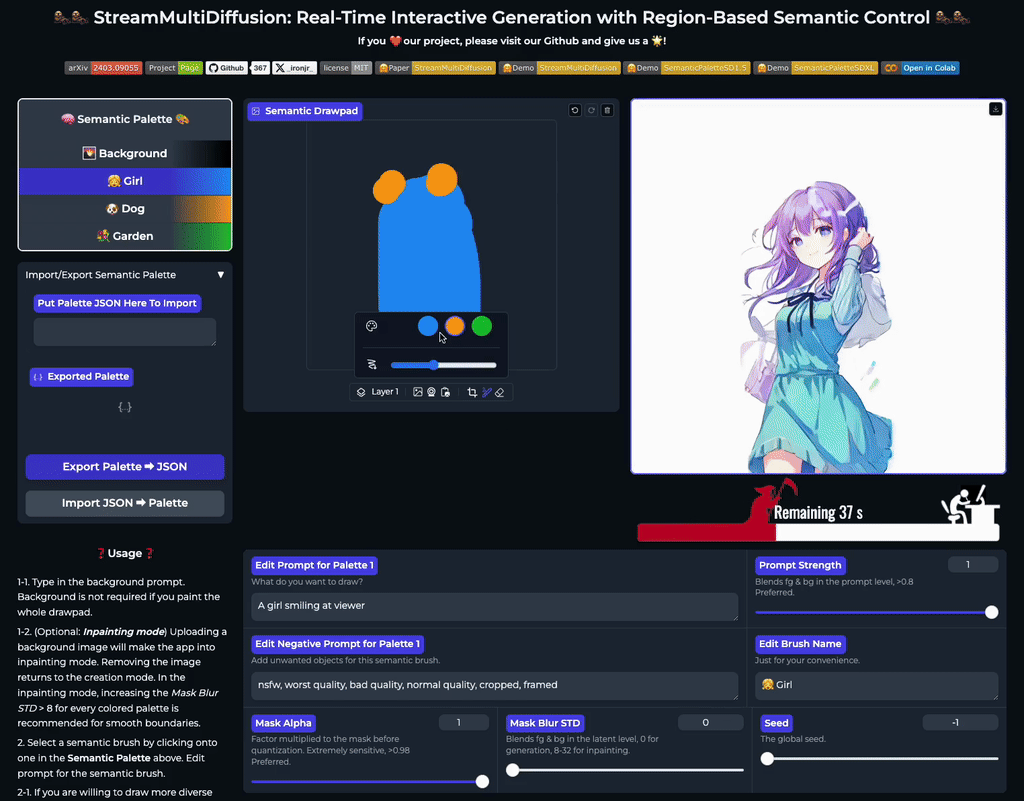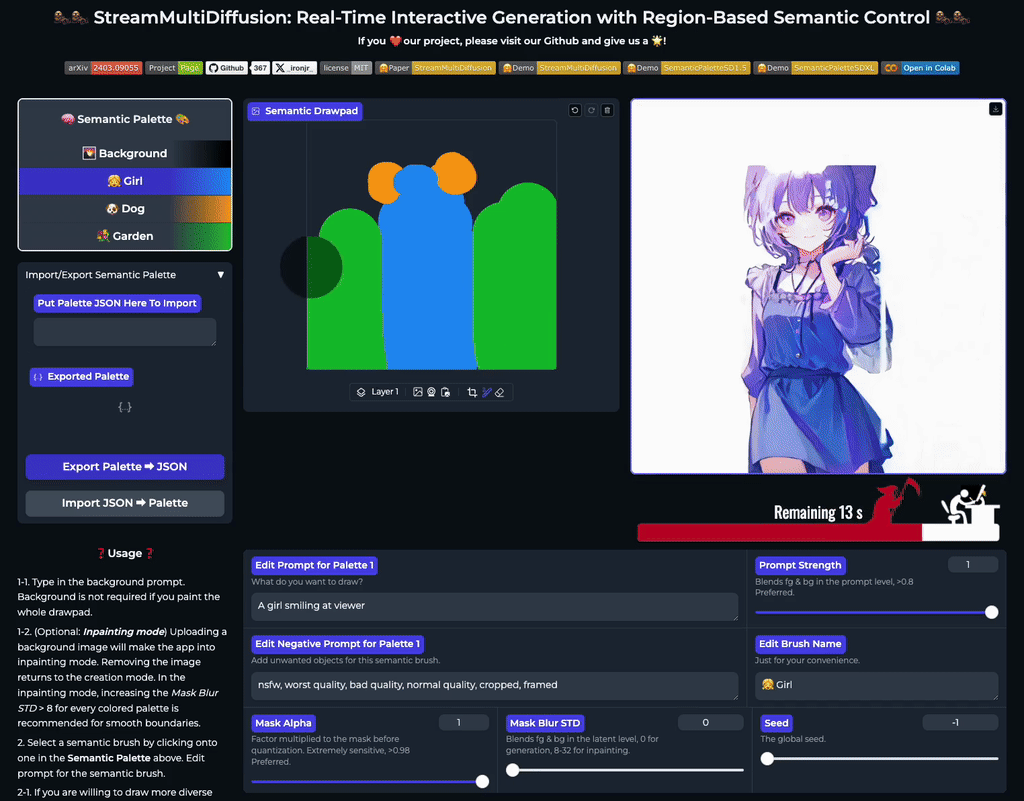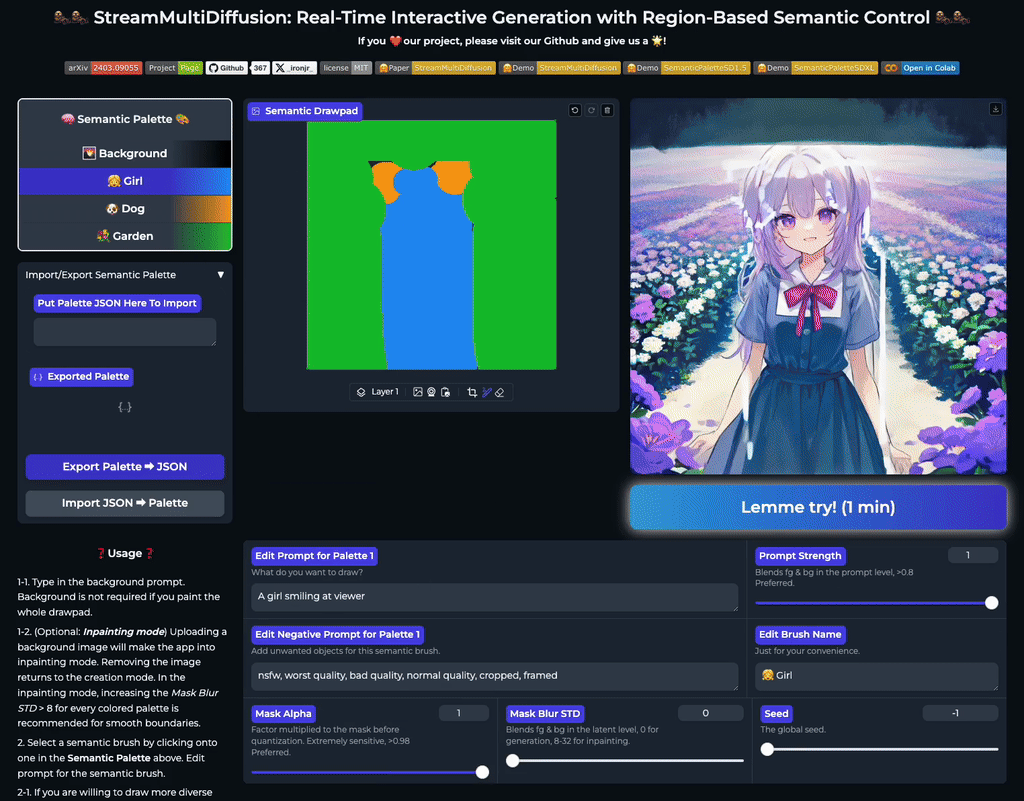
Our multi-prompt stream batch architecture allows fast, interactive generation with region-based controls. Try now from our code or wait until the demo is published online.
More Examples
Accelerated Text-to-Panorama Generation




Our acceleration technique speeds the generation of 512 x 3072 images up to 13 times faster than previous solution [1]. The time of inference is measured with a single 2080 Ti GPU.
Accelerated Region-Based Text-to-Image Generation

Our SemanticDraw can synthesize high-resolution images in seconds while strictly obeying the regional text prompts. The size of this generation is 768 x 1920 with nine prompts including the background prompt. The time is measured with a single 2080 Ti GPU.
BibTex
@inproceedings{lee2025semanticdraw,
title="{SemanticDraw:} Towards Real-Time Interactive Content Creation from Image Diffusion Models",
author={Lee, Jaerin and Jung, Daniel Sungho and Lee, Kanggeon and Lee, Kyoung Mu},
booktitle={CVPR},
year={2025}
}
Reference
[1] Bar-Tal, O., Yariv, L., Lipman, Y., Dekel, T.: MultiDiffusion: Fusing diffusion paths for controlled image generation. In ICML 2023.
[2] Luo, S., Tan, Y., Huang, L., Li, J., Zhao, H.: Latent Consistency Models: Synthesizing high-resolution images with few-step inference. arXiv preprint arXiv:2310.04378, 2023.
[3] Kodaira, A., Xu, C., Hazama, T., Yoshimoto, T., Ohno, K., Mitsuhori, S., Sugano, S., Cho, H., Liu, Z., Keutzer, K.: StreamDiffusion: A pipeline-level solution for real-time interactive generation. arXiv preprint arXiv:2312.12491, 2023.